
华为云服务器基于Milvus+ERNIE+SimCSE+In-batch Negatives样本策略的学术文献语义检索系统_云淘科技
基于Milvus+ERNIE+SimCSE+In-batch Negatives样本策略的学术文献语义检索系统
0.前言
语义索引(可通俗理解为向量索引)技术是搜索引擎、推荐系统、广告系统在召回阶段的核心技术之一。语义索引模型的目标是:给定输入文本,模型可以从海量候选召回库中快速、准确地召回一批语义相关文本。语义索引模型的效果直接决定了语义相关的物料能否被成功召回进入系统参与上层排序,从基础层面影响整个系统的效果。
0.1 为什么说语义搜索很重要?
尽管有无数的变量在起作用,但是语义搜索的原理,为什么需要它,以及它如何被影响,是很容易理解的。
用户使用的语言往往与所需内容不一样
很多搜索都在无意中产生歧义
了解词汇层级和实体关系的需要
反映个人兴趣和趋势的需要
0.1.1用户使用的语言往往与所需内容不一样:
更糟糕的是,我们有时甚至不知道如何正确表达我们想搜索的是什么。比方说,你在电台里听到了一首陌生的歌曲。你喜欢它,于是开始在Google上随机搜索歌词,直到你终于找到它为止。再增加一点复杂程度的话,将你在Google中输入的内容与对Siri,Alexa或Google智能助理的输入内容进行比较。 现在,关键字就变成了对话。表达同一个想法的方式太多了,搜索引擎需要处理所有这些方式。 搜索引擎需要能够根据两者的意义,将其索引中的内容与你的搜索查询进行匹配。
0.1.2 很多搜索都在无意中产生歧义,
大约40%的英语单词是多义词——它们有两个或更多的含义。这可以说是语义搜索要解决的最重大的挑战。例如,仅在美国,关键词 “python “的月搜索量就有53.3万次:
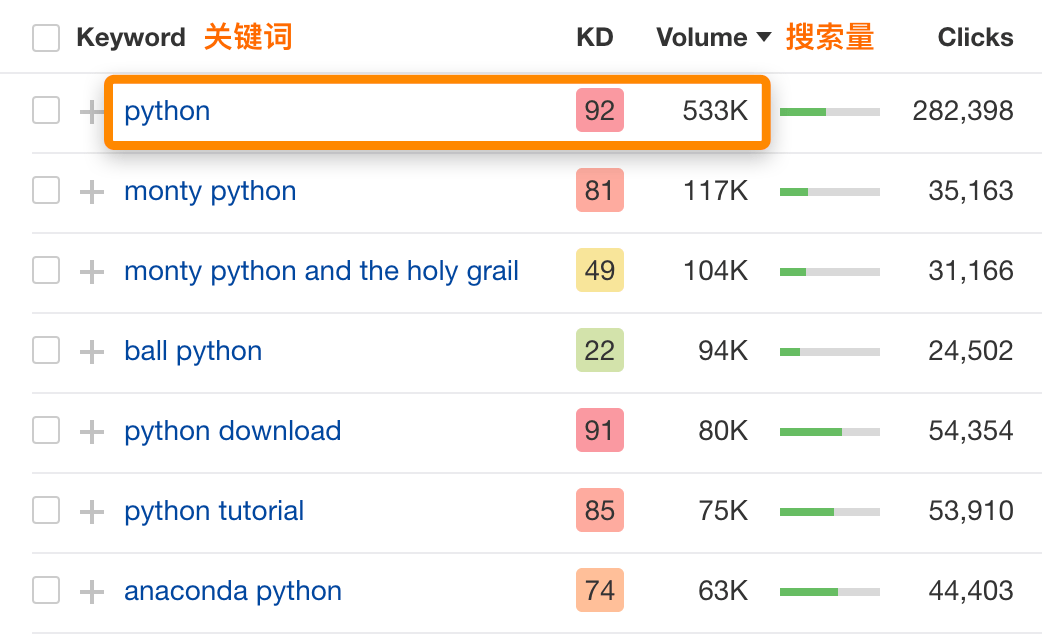
如果我曾经搜索过 “python”,我很可能指的是编程语言。但科技行业以外的人很可能会想到真正的蟒蛇,或者是传奇的英国喜剧团。这里的问题是,如果没有上下文,单词很少有明确的含义。在多义词的基础上,有无数的名词也可以同时是形容词,动词,或者两者兼而有之。而且我们还只是在谈论字面意思的范畴。如果我们深入研究其推论的话(譬如讽刺的时候),就会变得更加有趣。在语义学中,语境就是一切,这将为我们引出了接下来的两点。
0.1.3 了解词汇层级和实体关系的需要
让我们来看看以下的搜索查询和热门搜索结果:
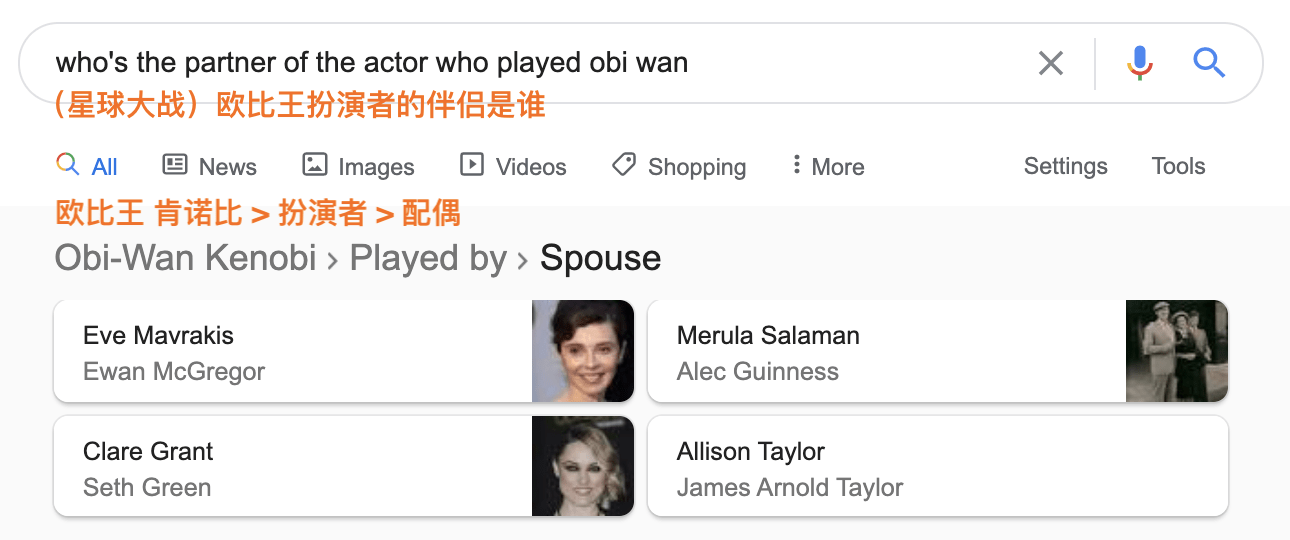
这确实非常厉害了。 以下是Google理解此查询必须要做的:
它要知道“伴侣 “是指妻子/女友/丈夫/男友/配偶。
了解到欧比王出现在多部电影和连续剧中,由不同的演员扮演。
建立联系。
以反映“欧比王”有歧义的方式来显示搜索结果。
词汇层级说明了单词之间的关系。 伴侣这个词对妻子,男友,配偶和其他词来说是上一级的(上位词)。
如前所述,我们的查询通常与所需内容的确切词组不匹配。 知道“负担得起”是介于便宜,中档和合理价格之间的任何事物,这一点至关重要。在此示例中,实体是电影和连续剧中的角色(欧比王),具有特定工作的人(演员)以及与之相关联的人(伴侣)。 通常,实体是可以明确识别的对象或概念-通常是人,地点和事物。
如果所有的这些语言的复杂性还不够的话,我们还必须再深入一些。
0.1.4 反映个人兴趣和趋势的需要
让我们回到“python”的例子。如果我搜索这个词,确实会得到所有与编程语言相关的结果。
无论我们多么不喜欢任何使用我们个人数据的方式,至少这对搜索引擎来说是有用的。Google结合了有限的数据和你的搜索历史,以提供更准确和个性化的搜索结果。我们都知道这一点。只要在搜索栏中输入任何类型的服务,你就会得到本地化的结果。
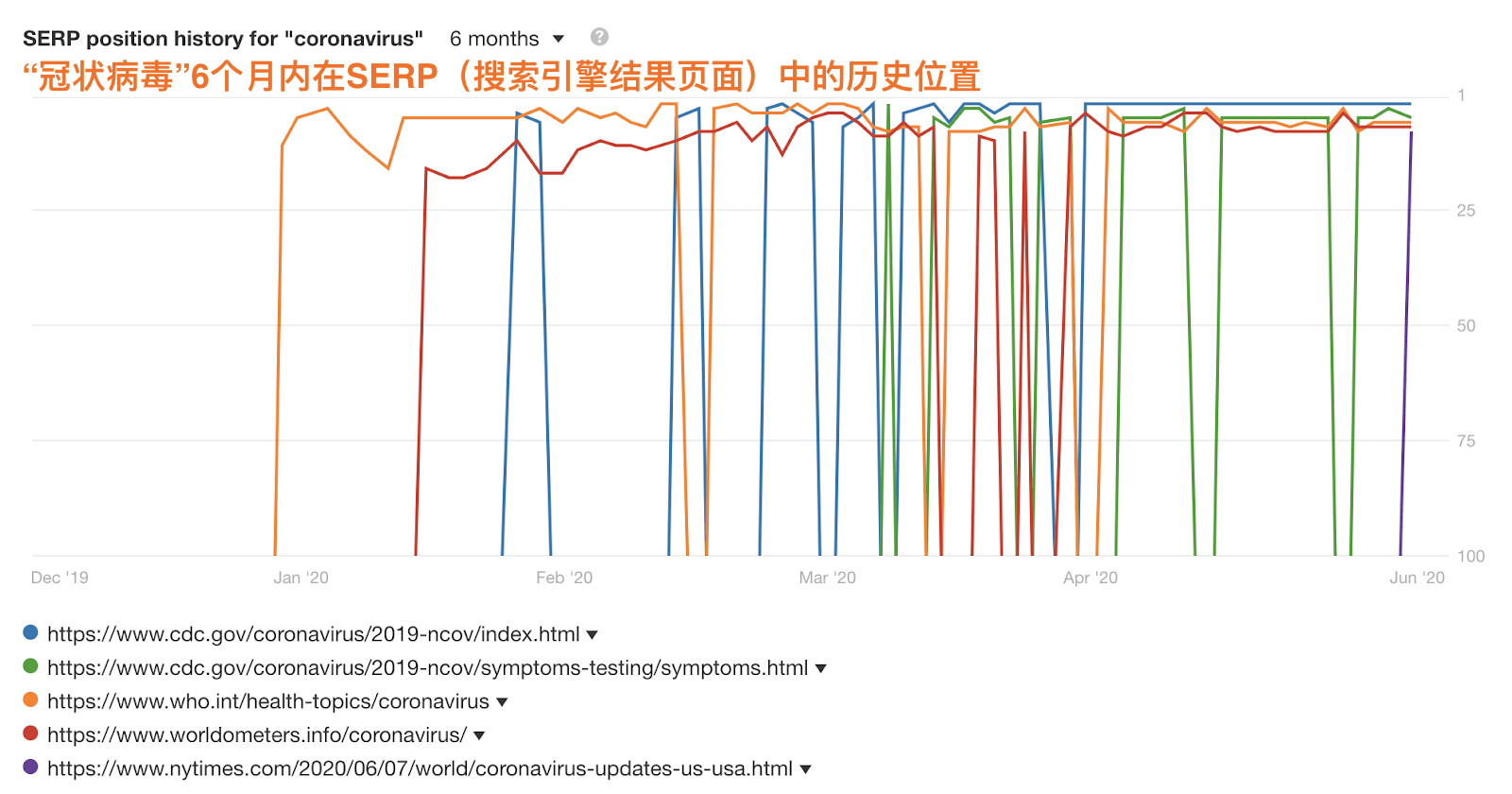
但更吸引人的是,谷歌能够根据动态变化的搜索意图临时调整搜索结果。
例如,冠状病毒不是一个新名词。 它一直是一组病毒的名称。 但众所周知,搜索意图在2020年初迅速改变。人们开始寻找有关特定冠状病毒(SARS-CoV‑2)的信息,因此必须对SERP进行相应的调整。
在召回阶段,最常见的方式是通过双塔模型,学习Document(简写为Doc)的向量表示,对Doc端建立索引,用ANN召回。我们在这种方式的基础上,引入语义索引策略 In-batch Negatives,以如下Batch size=4的训练数据为例:
我手机丢了,我想换个手机 我想买个新手机,求推荐
学日语软件手机上的 手机学日语的软件
侠盗飞车罪恶都市怎样改车 侠盗飞车罪恶都市怎么改车
In-batch Negatives 策略的训练数据为语义相似的 Pair 对,策略核心是在 1 个 Batch 内同时基于 N 个负例进行梯度更新,将Batch 内除自身之外其它所有 Source Text 的相似文本 Target Text 作为负例,例如: 上例中“我手机丢了,我想换个手机” 有 1 个正例(”我想买个新手机,求推荐“),2 个负例(1.手机学日语的软件,2.侠盗飞车罪恶都市怎么改车)。
0.2 哪些Google技术在语义搜索的工作方式中发挥了作用?
知识图谱
蜂鸟算法
RankBrain算法
BERT模型(大模型)
chatgpt
0.2.1 知识图谱
Google的知识图谱于2012年发布,是实体及实体之间关系的知识库。你可以想象它的样子大概是这样的-——但实际上有50亿个实体:
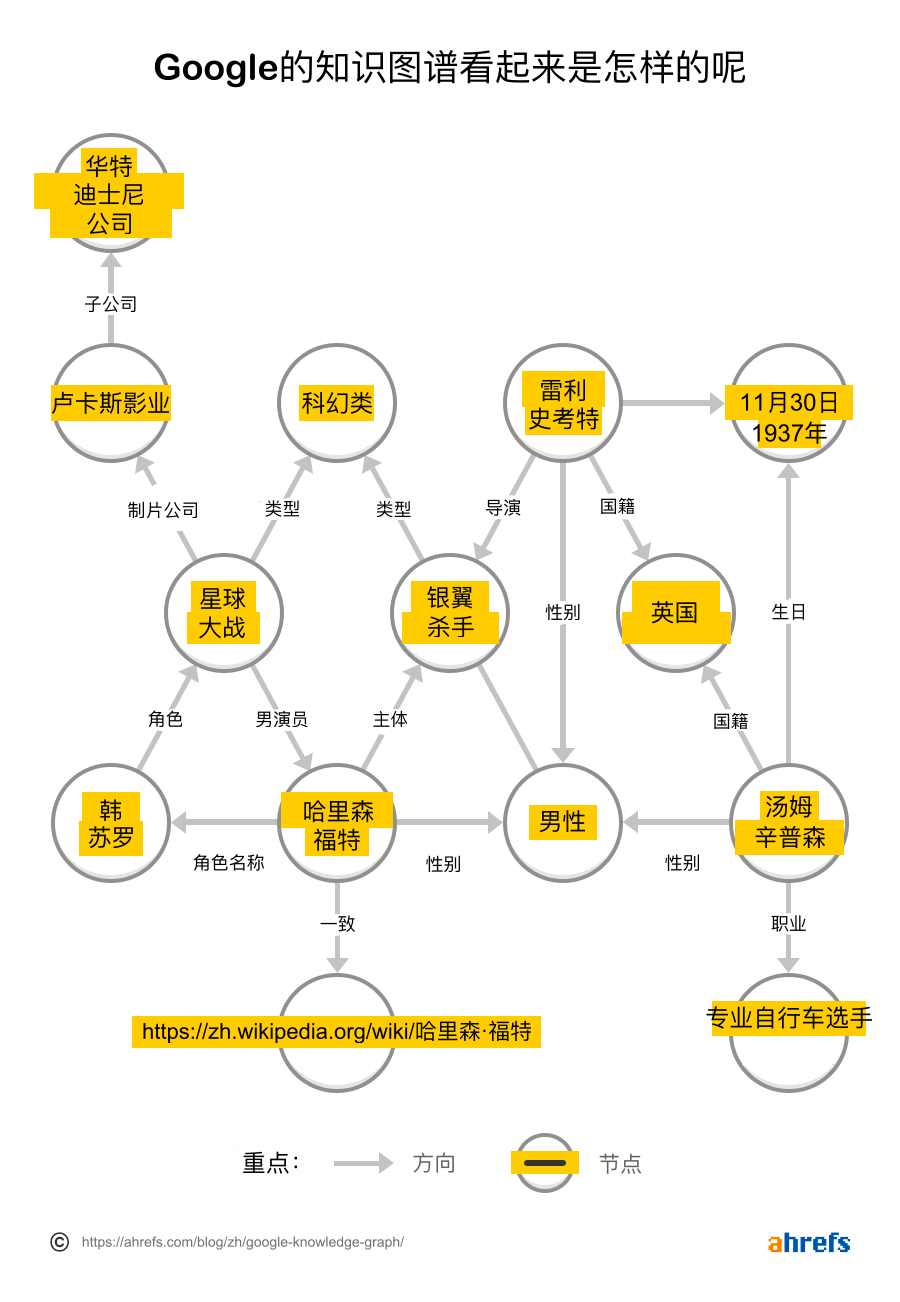
简而言之,这是一项启动并实现了从关键字匹配到语义匹配转变的技术。向知识图谱提供信息的方法主要有两种:
结构化数据(稍后详述)
从文本中提取实体
对于第二点,搜索引擎需要理解自然语言。这时候,下面三个算法的更新就会发挥作用。
0.2.2 蜂鸟算法
早在2013年,Google推出了一个名为Hummingbird(蜂鸟)的搜索算法,以返回更好的搜索结果。 这个算法尤其有助于应对复杂的搜索查询。蜂鸟算法是第一个重大更新,它更加强调搜索请求背后的意图,而非单个关键词。 它极速催化了“为话题而创作内容”的热潮,而不是“为单个关键词而写作”。
0.2.3 RankBrain算法
如果你曾经遇到过“潜在语义索引”或LSI关键词这一短语,可以忽略这个了。 Google用RankBrain算法解决了LSI产生的问题。而我们前面已经讨论过这个问题。是关于搜索请求中所使用的语言和所需内容之间的不匹配。Google的RankBrain采用了优于LSI的技术。通俗地说,通过使用复杂的机器学习算法,RankBrain甚至可以理解不熟悉的单词和短语的含义。而考虑到15%的搜索请求都是新的,这可是一项巨大的工程。我们可以认为RankBrain是蜂鸟算法的升级版,而不是一个独立的搜索算法。它是最强的排名信号之一,但你能主动为其做出的优化,也就只有满足搜索意图了。
0.2.4 BERT模型(大模型)
基于Transformer的双向编码器表示(BERT)这一自然语言表示模型,是对语义搜索运作方式的最新的重大升级。自2019年底以来,它影响了大约10%的查询。BERT可以提高对长而复杂的句子以及查询的理解。它是一种处理歧义和细微差别的解决方案,因为它力图更好地理解单词的上下文。
0.2.5 chatgpt
ChatGPT是美国人工智能研究实验室OpenAI新推出的一种人工智能技术驱动的自然语言处理工具,使用了Transformer神经网络架构,也是GPT-3.5架构,这是一种用于处理序列数据的模型,拥有语言理解和文本生成能力,尤其是它会通过连接大量的语料库来训练模型,这些语料库包含了真实世界中的对话,使得ChatGPT具备上知天文下知地理,还能根据聊天的上下文进行互动的能力,做到与真正人类几乎无异的聊天场景进行交流。ChatGPT不单是聊天机器人,还能进行撰写邮件、视频脚本、文案、翻译、代码等任务。
结合ChatGPT的底层技术逻辑,有媒体曾列出了中短期内ChatGPT的潜在产业化方向:归纳性的文字类工作、代码开发相关工作、图像生成领域、智能客服类工作。
核心竞争力
ChatGPT受到关注的重要原因是引入新技术RLHF (Reinforcement Learning with Human Feedback,即基于人类反馈的强化学习)。RLHF 解决了生成模型的一个核心问题,即如何让人工智能模型的产出和人类的常识、认知、需求、价值观保持一致。ChatGPT是AIGC(AI- Generated Content,人工智能生成内容)技术进展的成果。**该模型能够促进利用人工智能进行内容创作、提升内容生产效率与丰富度。 **
技术局限性
ChatGPT 的使用上还有局限性,模型仍有优化空间。ChatGPT模型的能力上限是由奖励模型决定,该模型需要巨量的语料来拟合真实世界,对标注员的工作量以及综合素质要求较高。ChatGPT可能会出现创造不存在的知识,或者主观猜测提问者的意图等问题,模型的优化将是一个持续的过程。若AI技术迭代不及预期,NLP模型优化受限,则相关产业发展进度会受到影响。此外,ChatGPT盈利模式尚处于探索阶段,后续商业化落地进展有待观察。
0.3 如何进行搜索引擎优化?
“SEO是指搜索引擎优化。全称为(Search Engine Optimization),是一种利用搜索引擎的规则提高网站在有关搜索引擎内自然排名的方式。目的是让其在行业内占据领先地位,获得品牌收益。
0.3.1 目标主题,而非关键词
在过去的SEO时代,你可以用关于同一主题的独立内容来获得高排名,但这里面定位的关键词会略有不同,如关键词:
open graph tags
open graph meta tags
og meta tags
open graph tag
what is open graph
facebook open graph tags
现在的情况已经不是这样了。Google现在明白,所有这些关键词搜索的意思都大同小异,并为所有这些搜索去排名基本相同的页面。在创建内容时要牢记这一点。我们的目的不再是只为一个关键词排名,而是要深入地探讨一个主题,这样Google才会为你的页面排名很多类似的长尾关键词。例如,我们关于Open Graph(开放图谱)元标签的文章在好几百个关键词中排名很好。其中很多是搜索同一事物的不同方式,但有些是 “og:title”、“og url “和 “og:image “这样的子话题。我们之所以能够在这些关键词下获得排名,是因为我们写了一篇关于这个主题的深度文章,而不仅仅是关于一个关键词。
想知道可以写些什么子话题的话,这里有个不错的办法:在这份报告里找到这个话题下的热门页面。例如,假设您想写一篇有关种植芦笋的文章。 如果将“种植芦笋”的排名靠前页面放到Ahrefs的网站分析并查看其自然搜索关键词报告,就会看到这个页面在这些关键词下都获得了排名,其中包括:
芦笋需要种植多深
芦笋种植条件
什么时候种植芦笋
芦笋的最佳种植地
如何收割芦笋
如何护理芦笋
如果你想通过创作一篇深度的贴文来获取尽可能多的自然流量,那么所有这些子话题都会是你应该提及的。不过要小心。 针对特定主题并不意味着你应该涵盖与该主题相关的所有内容,也不必太深入。
0.3.2评估搜索意图
你还是可以围绕某个主题来发布内容,即使这个主题是不符合搜索意图的。
假设你是一名营销数据极客,发现了“SEO报告”这个不错的话题。 自然地,你会希望分享制作最佳SEO报告所需要的东西。 因此,你会想到“利用搜索请求来创建最佳SEO报告”之类的内容。
确实,这可能是最终能造就最佳SEO报告的内容。 但是,大多数搜索此主题的人不熟悉许多Google表格功能。 他们只是想找到一些可以帮助他们完成工作的工具:
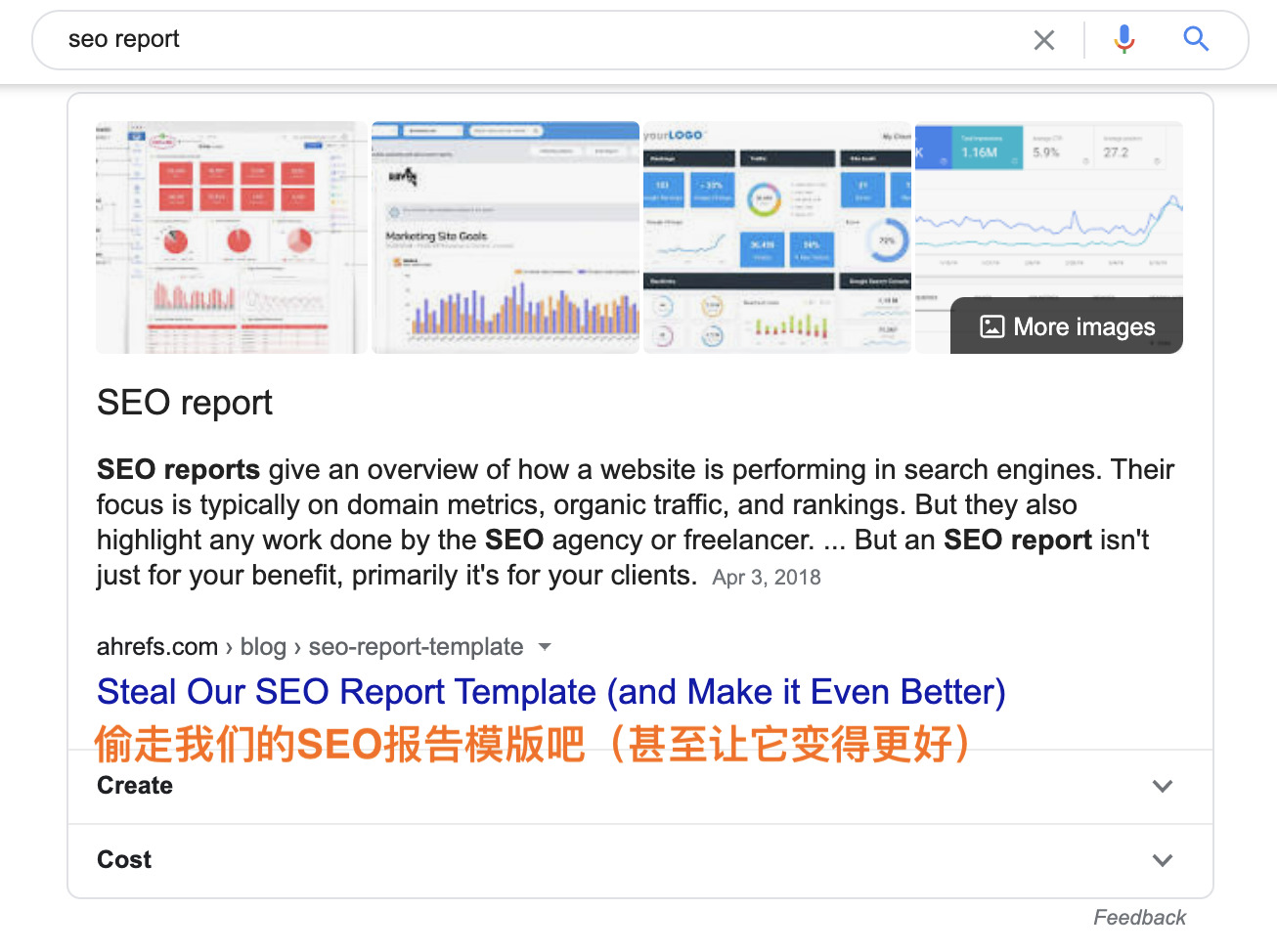
参考文章:搜索意图: 一个十分重要又经常被忽略的“排名要素”
0.3.3. 使用语义HTML
在我们还没法用上语义搜索的时候,我们不得已要转向语义网(Sematic Web)。 万维网(www)的原始概念可以解释为没有明确含义的、标准化的、互相链接的文档。 然而现在,显然我们需要“含义”。
这得从你的基本HTML开始说起。我们先来比较以下的HTML元素:

语义HTML为代码增加了含义,因此机器可以识别导航模块,页眉,页脚,表格或视频。HTML5则提供了最多的语义元素,大多数现代CMS主题都会使用这些元素。如果你还没有的话,通常一个插件就可以添加好。但是语义HTML仍然非常有限。 虽然它有指示出来:“这是一个表格,这是一个页脚”,但它没办法实际内容的含义。这就是为什么我们需要把这些标记结构化(schema)。
0.3.4. 使用Scheme标记
Schema标记是标记你的网页的另一种方式。它也被称为结构化数据,可以说是网络的一个通用语义框架。Schema.org.cn词汇表包含与属性相关联的数百种schema标记类型。 你可以使用这些来标记你的内容,让Google无需复杂的算法即可轻松理解。
例如,Google会更容易从这样的结构化内容中提取含义:
烹饪时间:20分钟
卡路里:80
这比直接从原文中提取含义容易多了:
制作煎饼需要20分钟。 更理想的是,这些是低热量的煎饼——每份约80卡路里。
这样一来,当用户想知道做一块煎饼需要多长时间,或者它有多少卡路里时,Google可以以最佳的方式提供信息。
参考文章:https://ahrefs.com/blog/rich-snippets/
文章参考:https://ahrefs.com/blog/zh/?p=1670
1.学术文献检索系统搭建一个语义检索系统
语义搜索系列文章全流程教学:
语义检索系统:基于无监督预训练语义索引召回:SimCSE、Diffcse:
语义检索系统:基于in-batch Negatives策略的有监督训练语义召回:
语义检索系统:基于Milvus 搭建召回系统抽取向量进行检索,加速索引:
语义检索系统:基于ERNIE-Gram /RocketQA实现数据精排序:
基于Milvus+ERNIE+SimCSE+IBN实现学术文献语义检索系统完整版:
更多文本匹配方案参考:
特定领域知识图谱融合方案:技术知识前置【一】-文本匹配算法:
特定领域知识图谱融合方案:文本匹配算法Simnet、Diffcse【二】:
特定领域知识图谱融合方案:文本匹配算法ERNIE-Gram单塔等诸多模型【三】:
基于文心大模型套件ERNIEKit实现文本匹配算法:
特定领域知识图谱融合方案:学以致用-问题匹配鲁棒性评测比赛验证【四】:
效果预览:
性能对比:
| 硬件配置 | 向量库数据量 | 提取特征所需时间 | milvus检索所需时间 | 排序所需时间 | 总耗时 |
|---|---|---|---|---|---|
| CPU 12核 2.5GHz | 1000w 大小45GB左右 | 64.5ms | 258.3ms | 871.6 ms | 1.19s |
| CPU + Tesla V100 32G | 1000w 大小45GB左右 | 10ms | 213.6ms | 24.1ms | 0.25s |
场景概述
检索系统存在于我们日常使用的很多产品中,比如商品搜索系统、学术文献检索系等等,本方案提供了检索系统完整实现。限定场景是用户通过输入检索词 Query,快速在海量数据中查找相似文档。
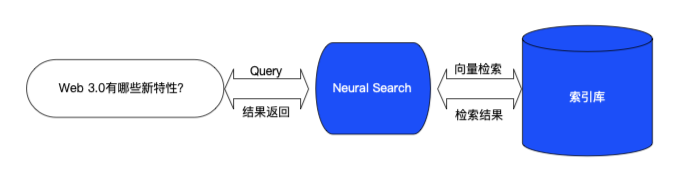
所谓语义检索(也称基于向量的检索,如上图所示),是指检索系统不再拘泥于用户 Query 字面本身,而是能精准捕捉到用户 Query 后面的真正意图并以此来搜索,从而更准确地向用户返回最符合的结果。通过使用最先进的语义索引模型找到文本的向量表示,在高维向量空间中对它们进行索引,并度量查询向量与索引文档的相似程度,从而解决了关键词索引带来的缺陷。
例如下面两组文本 Pair,如果基于关键词去计算相似度,两组的相似度是相同的。而从实际语义上看,第一组相似度高于第二组。
车头如何放置车牌 前牌照怎么装
车头如何放置车牌 后牌照怎么装
语义检索系统的关键就在于,采用语义而非关键词方式进行召回,达到更精准、更广泛得召回相似结果的目的。想快速体验搜索的效果,请参考Pipelines的语义检索实现

通常检索业务的数据都比较庞大,都会分为召回(索引)、排序两个环节。召回阶段主要是从至少千万级别的候选集合里面,筛选出相关的文档,这样候选集合的数目就会大大降低,在之后的排序阶段就可以使用一些复杂的模型做精细化或者个性化的排序。一般采用多路召回策略(例如关键词召回、热点召回、语义召回结合等),多路召回结果聚合后,经过统一的打分以后选出最优的 TopK 的结果。
1.1内容简介
低门槛
手把手搭建起检索系统
无需标注数据也能构建检索系统
提供 训练、预测、ANN 引擎一站式能力
Pipelines 快速实现语义检索系统
效果好
针对多种数据场景的专业方案
仅有无监督数据: SimCSE
仅有有监督数据: InBatchNegative
兼具无监督数据 和 有监督数据:融合模型
进一步优化方案: 面向领域的预训练 Domain-adaptive Pretraining
性能快
Paddle Inference 快速抽取向量
Milvus 快速查询和高性能建库
Paddle Serving服务化部署
1.2 功能架构
索引环节有两类方法:基于字面的关键词索引;语义索引。语义索引能够较好地表征语义信息,解决字面不相似但语义相似的情形。本系统给出的是语义索引方案,实际业务中可融合其他方案使用。下面就详细介绍整个方案的架构和功能。
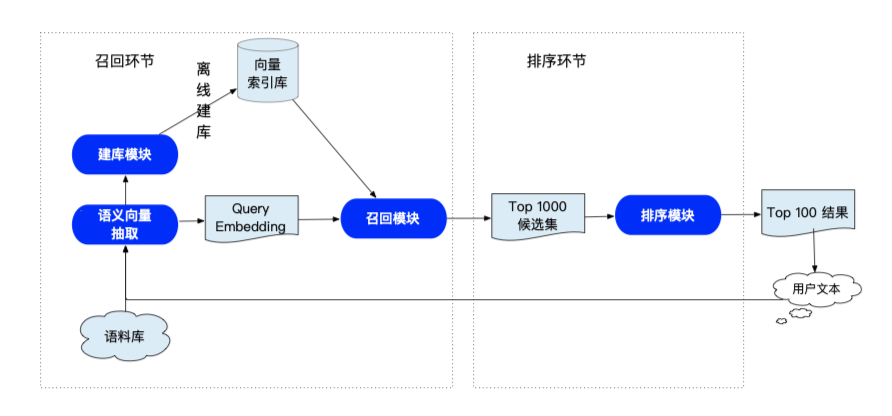
以上是nerual_search的系统流程图,其中左侧为召回环节,核心是语义向量抽取模块;右侧是排序环节,核心是排序模型。召回环节需要用户通过自己的语料构建向量索引库,用户发起query了之后,就可以检索出相似度最高的向量,然后找出该向量对应的文本;排序环节主要是对召回的文本进行重新排序。下面我们分别介绍召回中的语义向量抽取模块,以及排序模型。
1.2.1 召回模块
召回模块需要从千万量级数据中快速召回候选数据。首先需要抽取语料库中文本的 Embedding,然后借助向量搜索引擎实现高效 ANN,从而实现候选集召回。
我们针对不同的数据情况推出三种语义索引方案,如下图所示,您可以参照此方案,快速建立语义索引:
| ⭐️ 无监督数据 | ⭐️ 有监督数据 | 召回方案 |
|---|---|---|
| 多 | 无 | SimCSE |
| 无 | 多 | In-batch Negatives |
| 有 | 有 | SimCSE+ In-batch Negatives |
最基本的情况是只有无监督数据,我们推荐您使用 SimCSE 进行无监督训练;另一种方案是只有有监督数据,我们推荐您使用 In-batch Negatives 的方法进行有监督训练。
如果想进一步提升模型效果:还可以使用大规模业务数据,对预训练模型进行 Domain-adaptive Pretraining,训练完以后得到预训练模型,再进行无监督的 SimCSE。
此外,如果您同时拥有监督数据和无监督数据,我们推荐将两种方案结合使用,这样能训练出更加强大的语义索引模型。
1.2.2 排序模块
召回模型负责从海量(千万级)候选文本中快速(毫秒级)筛选出与 Query 相关性较高的 TopK Doc,排序模型会在召回模型筛选出的 TopK Doc 结果基础之上针对每一个 (Query, Doc) Pair 对进行两两匹配计算相关性,排序效果更精准。
排序模块有2种选择,第一种基于前沿的预训练模型 ERNIE,训练 Pair-wise 语义匹配模型;第二种是基于RocketQA模型训练的Cross Encoder模形。第一种是Pair-wise的排序算法,基本思路是对样本构建偏序文档对,两两比较,从比较中学习顺序,第二种是Poinet-Wise的算法,只考虑当前Query和每个文档的绝对相关度,并没有考虑其他文档与Query的相关度,但是建模方式比较简单。第一种Pair-wise模型可以说是第二种point-wise模型的改进版本,但对于噪声数据更为敏感,即一个错误的标注会导致多个pair对的错误,用户可以先使用基于Point-wise的Cross Encoder构建一个基础模型,需要进一步优化可以使用Pair-wise的方法优化。
2. 文献检索实践
2.1 技术方案和评估指标
2.1.1 技术方案
语义索引:由于我们既有无监督数据,又有有监督数据,所以结合 SimCSE 和 In-batch Negatives 方案,并采取 Domain-adaptive Pretraining 优化模型效果。
首先是利用 ERNIE模型进行 Domain-adaptive Pretraining,在得到的预训练模型基础上,进行无监督的 SimCSE 训练,最后利用 In-batch Negatives 方法进行微调,得到最终的语义索引模型,把建库的文本放入模型中抽取特征向量,然后把抽取后的向量放到语义索引引擎 milvus 中,利用 milvus 就可以很方便得实现召回了。
排序:使用 ERNIE-Gram 的单塔结构/RocketQA的Cross Encoder对召回后的数据精排序。
2.1.2 评估指标
模型效果指标
在语义索引召回阶段使用的指标是 Recall@K,表示的是预测的前topK(从最后的按得分排序的召回列表中返回前K个结果)结果和语料库中真实的前 K 个相关结果的重叠率,衡量的是检索系统的查全率。
在排序阶段使用的指标为AUC,AUC反映的是分类器对样本的排序能力,如果完全随机得对样本分类,那么AUC应该接近0.5。分类器越可能把真正的正样本排在前面,AUC越大,分类性能越好。
性能指标
基于 Paddle Inference 快速抽取向量
建库性能和 ANN 查询性能快
2.2 预置数据说明
数据集来源于某文献检索系统,既有大量无监督数据,又有有监督数据。
(1)采用文献的 query, title,keywords,abstract 四个字段内容,构建无标签数据集进行 Domain-adaptive Pretraining;
(2)采用文献的 query,title,keywords 三个字段内容,构造无标签数据集,进行无监督召回训练SimCSE;
(3)使用文献的query, title, keywords,构造带正标签的数据集,不包含负标签样本,基于 In-batch Negatives 策略进行训练;
(4)在排序阶段,使用点击(作为正样本)和展现未点击(作为负样本)数据构造排序阶段的训练集,进行精排训练。
| 阶段 | 模型 | 训练集 | 评估集(用于评估模型效果) | 召回库 | 测试集 |
|---|---|---|---|---|---|
| 召回 | Domain-adaptive Pretraining | 2kw | – | – | – |
| 召回 | 无监督预训练 – SimCSE | 798w | 20000 | 300000 | 1000 |
| 召回 | 有监督训练 – In-batch Negatives | 3998 | 20000 | 300000 | 1000 |
| 排序 | 有监督训练 – ERNIE-Gram单塔 Pairwise/RocketQA Cross Encoder | 1973538 | 57811 | – | 1000 |
├── milvus # milvus建库数据集
├── milvus_data.csv. # 构建召回库的数据(模拟实际业务线上的语料库,实际语料库远大于这里的规模),用于直观演示相关文献召回效果
├── recall # 召回阶段数据集
├── train_unsupervised.csv # 无监督训练集,用于训练 SimCSE
├── train.csv # 有监督训练集,用于训练 In-batch Negative
├── dev.csv # 召回阶段验证集,用于评估召回模型的效果,SimCSE 和 In-batch Negative 共用
├── corpus.csv # 构建召回库的数据(模拟实际业务线上的语料库,实际语料库远大于这里的规模),用于评估召回阶段模型效果,SimCSE 和 In-batch Negative 共用
├── test.csv # 召回阶段测试数据,预测文本之间的相似度,SimCSE 和 In-batch Negative 共用
├── data # RocketQA排序数据集
├── test.csv # 测试集
├── dev_pairwise.csv # 验证集
└── train.csv # 训练集
├── sort # 排序阶段数据集
├── train_pairwise.csv # 排序训练集
├── dev_pairwise.csv # 排序验证集
└── test_pairwise.csv # 排序测试集
2.3 数据格式
对于无监督SimCSE的训练方法,格式参考train_unsupervised.csv,即一行条文本即可,无需任何标注。对于召回模型训练需要规定格式的本地数据集,需要准备训练集文件train.csv,验证集dev.csv,召回集文件corpus.csv。
训练数据集train.csv的格式如下:
query1 用户点击的title1
query2 用户点击的title2
训练集合train.csv的文件样例:
从《唐律疏义》看唐代封爵贵族的法律特权 从《唐律疏义》看唐代封爵贵族的法律特权《唐律疏义》,封爵贵族,法律特权
宁夏社区图书馆服务体系布局现状分析 宁夏社区图书馆服务体系布局现状分析社区图书馆,社区图书馆服务,社区图书馆服务体系
人口老龄化对京津冀经济 京津冀人口老龄化对区域经济增长的影响京津冀,人口老龄化,区域经济增长,固定效应模型
英语广告中的模糊语 模糊语在英语广告中的应用及其功能模糊语,英语广告,表现形式,语用功能
甘氨酸二肽的合成 甘氨酸二肽合成中缩合剂的选择甘氨酸,缩合剂,二肽
......
验证集dev.csv的格式如下:
query1 用户点击的title1
query2 用户点击的title2
验证集合train.csv的文件样例:
试论我国海岸带经济开发的问题与前景 试论我国海岸带经济开发的问题与前景海岸带,经济开发,问题,前景
外语阅读焦虑与英语成绩及性别的关系 外语阅读焦虑与英语成绩及性别的关系外语阅读焦虑,外语课堂焦虑,英语成绩,性别
加油站风险分级管控 加油站工作危害风险分级研究加油站,工作危害分析(JHA),风险分级管控
召回集合corpus.csv主要作用是检验测试集合的句子对能否被正确召回,它的构造主要是提取验证集的第二列的句子,然后加入很多无关的句子,用来检验模型能够正确的从这些文本中找出测试集合对应的第二列的句子,格式如下:
2002-2017年我国法定传染病发病率和死亡率时间变化趋势传染病,发病率,死亡率,病死率
陕西省贫困地区城乡青春期少女生长发育调查青春期,生长发育,贫困地区
五丈岩水库溢洪道加固工程中的新材料应用碳纤维布,粘钢加固技术,超细水泥,灌浆技术
......
对于排序模型的训练,排序模型目前提供了2种,第一种是Pairwise训练的方式,第二种是RocketQA的排序模型,对于第一种排序模型,需要准备训练集train_pairwise.csv,验证集dev_pairwise.csv两个文件,除此之外还可以准备测试集文件test.csv或者test_pairwise.csv。
训练数据集train_pairwise.csv的格式如下:
query1 用户点击的title1 用户未点击的title2
query2 用户点击的title3 用户未点击的title4
训练数据集train_pairwise.csv的示例如下:
英语委婉语引起的跨文化交际障碍 英语委婉语引起的跨文化交际障碍及其翻译策略研究英语委婉语,跨文化交际障碍,翻译策略 委婉语在英语和汉语中的文化差异委婉语,文化,跨文化交际
范迪慧 嘉兴市中医院 滋阴疏肝汤联合八穴隔姜灸治疗肾虚肝郁型卵巢功能低下的临床疗效滋阴疏肝汤,八穴隔姜灸,肾虚肝郁型卵巢功能低下,性脉甾类激素,妊娠 温针灸、中药薰蒸在半月板损伤术后康复中的疗效分析膝损伤,半月板,胫骨,中医康复,温针疗法,薰洗
......
验证数据集dev_pairwise.csv的格式如下:
query1 title1 label
query2 title2 label
验证数据集dev_pairwise.csv的示例如下:
作者单位:南州中学 浅谈初中教学管理如何体现人文关怀初中教育,教学管理,人文关怀 1
作者单位:南州中学 高中美术课堂教学中藏区本土民间艺术的融入路径藏区,传统民间艺术,美术课堂 0
作者单位:南州中学 列宁关于资产阶级民主革命向 社会主义革命过渡的理论列宁,直接过渡,间接过渡,资产阶级民主革命,社会主义革命 0
DAA髋关节置换 DAA前侧入路和后外侧入路髋关节置换疗效对比髋关节置换术;直接前侧入路;后外侧入路;髋关节功能;疼痛;并发症 1
DAA髋关节置换 DAA全髋关节置换术治疗髋关节病变对患者髋关节运动功能的影响直接前侧入路全髋关节置换术,髋关节病变,髋关节运动功能 0
DAA髋关节置换 护患沟通技巧在急诊输液护理中的应用分析急诊科,输液护理,护理沟通技巧,应用 0
.......
训练数据集test_pairwise.csv的格式如下,其中这个score得分是召回算出来的相似度或者距离,仅供参考,可以忽略:
query1 title1 score
query2 title2 score
训练数据集test_pairwise.csv的示例如下:
中西方语言与文化的差异 中西方文化差异以及语言体现中西方文化,差异,语言体现 0.43203747272491455
中西方语言与文化的差异 论中西方文化差异在非言语交际中的体现中西方文化,差异,非言语交际 0.4644506871700287
中西方语言与文化的差异 中西方体态语文化差异跨文化,体态语,非语言交际,差异 0.4917311668395996
中西方语言与文化的差异 由此便可以发现两种语言以及两种文化的差异。 0.5039259195327759
.......
对于第二种基于RocketQA的排序模型。
训练数据集train.csv,验证集dev_pairwise.csv的格式如下:
query1 title1 label
query2 title2 label
训练数据集train.csv,验证集dev_pairwise.csv的示例如下:
(小学数学教材比较) 关键词:新加坡 新加坡与中国数学教材的特色比较数学教材,教材比较,问题解决 0
徐慧新疆肿瘤医院 头颈部非霍奇金淋巴瘤扩散加权成像ADC值与Ki-67表达相关性分析淋巴瘤,非霍奇金,头颈部肿瘤,磁共振成像 1
抗生素关性腹泻 鼠李糖乳杆菌GG防治消化系统疾病的研究进展鼠李糖乳杆菌,腹泻,功能性胃肠病,肝脏疾病,幽门螺杆菌 0
德州市图书馆 图书馆智慧化建设与融合创新服务研究图书馆;智慧化;阅读服务;融合创新 1
维生素c 综述 维生素C防治2型糖尿病研究进展维生素C;2型糖尿病;氧化应激;自由基;抗氧化剂 0
.......
训练数据集test.csv的格式如下,其中这个score得分是召回算出来的相似度或者距离,仅供参考,可以忽略:
query1 title1 score
query2 title2 score
训练数据集test.csv的示例如下:
加强科研项目管理有效促进医学科研工作 科研项目管理策略科研项目,项目管理,实施,必要性,策略 0.32163668
加强科研项目管理有效促进医学科研工作 关于推进我院科研发展进程的相关问题研究医院科研,主体,环境,信息化 0.32922596
加强科研项目管理有效促进医学科研工作 深圳科技计划对高校科研项目资助现状分析与思考基础研究,高校,科技计划,科技创新 0.36869502
加强科研项目管理有效促进医学科研工作 普通高校科研管理模式的优化与创新普通高校,科研,科研管理 0.3688045
.......
#解压数据集
# !unzip -d /home/aistudio/literature_search_data /home/aistudio/data/data225060/literature_search_data.zip
# !unzip -d /home/aistudio/literature_search_rank /home/aistudio/data/data225060/literature_search_rank.zip
# !unzip /home/aistudio/neural_search.zip
import csv
def show_data(filename, num_rows=10):
with open(filename, 'r') as f:
reader = csv.reader(f)
header = next(reader) # 获取表头
print(header) # 打印表头
for i, row in enumerate(reader):
if i < num_rows: # 打印前num_rows行数据
print(row)
else:
break
line = '-' * 50
print(line)
show_data('/home/aistudio/literature_search_data/milvus/milvus_data.csv', num_rows=5)
show_data('/home/aistudio/literature_search_data/recall/train_unsupervised.csv', num_rows=5)
show_data('/home/aistudio/literature_search_data/recall/train.csv', num_rows=5)
show_data('/home/aistudio/literature_search_data/recall/dev.csv', num_rows=5)
show_data('/home/aistudio/literature_search_data/recall/corpus.csv', num_rows=5)
show_data('/home/aistudio/literature_search_data/recall/test.csv', num_rows=5)
['wodem又出了花月瑶的鞋']
['黄电容信仰加持']
['15、andy从废柴到欧洲巡演发唱片到学会了一个人生活,errol长大了声线粗了也有了自己的同龄朋友,这是我看过最好的英剧前三。']
['结语:随着国家“二孩”政策的放开,越来越多的消费者倾向于购买空间更宽敞,舒适性更强的mpv车型。']
['玩一慧?']
['Study of New Driving Force for Quality Improvement of the Cultivation of Applied College Talents - Centering on Career Planning for College Students']
--------------------------------------------------
['煤矸石-污泥基活性炭介导强化污水厌氧消化']
['煤矸石-污泥基活性炭介导强化污水厌氧消化煤矸石', '污泥', '复合基活性炭', '厌氧消化', '直接种间电子传递']
['. 睡眠障碍与常见神经系统疾病的关系']
['睡眠障碍与常见神经系统疾病的关系睡眠觉醒障碍', '神经系统疾病', '睡眠', '快速眼运动', '细胞增殖', '阿尔茨海默病']
['城市道路交通流中观仿真研究']
['城市道路交通流中观仿真研究智能运输系统;城市交通管理;计算机仿真;城市道路;交通流;路径选择']
--------------------------------------------------
['从《唐律疏义》看唐代封爵贵族的法律特权 从《唐律疏义》看唐代封爵贵族的法律特权《唐律疏义》', '封爵贵族', '法律特权']
['宁夏社区图书馆服务体系布局现状分析 宁夏社区图书馆服务体系布局现状分析社区图书馆', '社区图书馆服务', '社区图书馆服务体系']
['人口老龄化对京津冀经济 京津冀人口老龄化对区域经济增长的影响京津冀', '人口老龄化', '区域经济增长', '固定效应模型']
['英语广告中的模糊语 模糊语在英语广告中的应用及其功能模糊语', '英语广告', '表现形式', '语用功能']
['甘氨酸二肽的合成 甘氨酸二肽合成中缩合剂的选择甘氨酸', '缩合剂', '二肽']
['玉米农田生态系统水碳通量日变化特征研究 玉米农田生态系统水碳通量日变化特征研究玉米农田', '水汽通量', 'CO2通量', '冠层导度', '日变化']
--------------------------------------------------
['热处理对尼龙6 及其与聚酰胺嵌段共聚物共混体系晶体熔融行为和结晶结构的影响 热处理对尼龙6及其与聚酰胺嵌段共聚物共混体系晶体熔融行为和结晶结构的影响尼龙6', '聚酰胺嵌段共聚物', '芳香聚酰胺', '热处理']
['面向生态系统服务的生态系统分类方案研发与应用. 面向生态系统服务的生态系统分类方案研发与应用']
['huntington舞蹈病的动物模型 Huntington舞蹈病的动物模型']
['试论我国海岸带经济开发的问题与前景 试论我国海岸带经济开发的问题与前景海岸带', '经济开发', '问题', '前景']
['外语阅读焦虑与英语成绩及性别的关系 外语阅读焦虑与英语成绩及性别的关系外语阅读焦虑', '外语课堂焦虑', '英语成绩', '性别']
['加油站风险分级管控 加油站工作危害风险分级研究加油站', '工作危害分析(JHA)', '风险分级管控']
--------------------------------------------------
['2002-2017年我国法定传染病发病率和死亡率时间变化趋势传染病', '发病率', '死亡率', '病死率']
['陕西省贫困地区城乡青春期少女生长发育调查青春期', '生长发育', '贫困地区']
['五丈岩水库溢洪道加固工程中的新材料应用碳纤维布', '粘钢加固技术', '超细水泥', '灌浆技术']
['木塑复合材料在儿童卫浴家具中的应用探索木塑复合材料', '儿童', '卫浴家具']
['泡沫铝准静态轴向压缩有限元仿真泡沫铝', '准静态', '轴向压缩', '力学特性']
['An Analysis of the Potential of Import and Export Trade between China and the Countries along the Belt and Road']
--------------------------------------------------
['加强科研项目管理有效促进医学科研工作 加强科研项目管理有效促进医学科研工作']
['\胶原蛋白的研究进展\ 基因工程技术生产重组胶原蛋白的研究进展胶原蛋白', '基因工程', '大肠杆菌', '毕赤酵母']
['怎样正确认识中华民族迎来了从站起来、富起来到强起来的伟大飞跃 怎样正确认识中华民族迎来了从站起来、富起来到强起来的伟大飞跃中国特色社会主义', '新时代', '伟大飞跃', '中国梦']
['TK“保险+医养”商业模式案例分析 TK“保险+医养”商业模式案例分析寿险产业链;医养融合;商业模式']
['谱系示踪建立动物模型 SPC-Cre转基因小鼠的建立Cre重组酶;SPC启动子;转基因;肺泡上皮细胞;动物模型']
['基于Node-RED ——以中职物联网专业系统开发课程为例']
--------------------------------------------------
show_data('/home/aistudio/literature_search_data/sort/train_pairwise.csv', num_rows=5)
show_data('/home/aistudio/literature_search_data/sort/dev_pairwise.csv', num_rows=5)
show_data('/home/aistudio/literature_search_data/sort/test_pairwise.csv', num_rows=5)
['query title neg_title']
['英语委婉语引起的跨文化交际障碍 英语委婉语引起的跨文化交际障碍及其翻译策略研究英语委婉语', '跨文化交际障碍', '翻译策略 委婉语在英语和汉语中的文化差异委婉语', '文化', '跨文化交际']
['范迪慧 嘉兴市中医院 滋阴疏肝汤联合八穴隔姜灸治疗肾虚肝郁型卵巢功能低下的临床疗效滋阴疏肝汤', '八穴隔姜灸', '肾虚肝郁型卵巢功能低下', '性脉甾类激素', '妊娠 温针灸、中药薰蒸在半月板损伤术后康复中的疗效分析膝损伤', '半月板', '胫骨', '中医康复', '温针疗法', '薰洗']
['灰色关联分析 灰色关联分析评价不同产地金果榄质量金果榄;灰色关联分析法;主成分分析法;盐酸巴马汀;盐酸药根碱 江西省某三级甲等医院2型糖尿病患者次均住院费用新灰色关联分析2型糖尿病', '次均住院费用', '新灰色关联分析', '结构变动度']
['护理质量管理进展 病区分类管理在护理工作中的应用进展综述', '病区分类', '护理管理 介入手术室的护理安全管理研究进展介入手术室;护理安全管理;护理质量;研究进展']
['血糖波动认知功能障碍 老年糖尿病患者血糖波动与认知功能障碍关系的研究进展老年人', '糖尿病', '认知功能', '血糖波动 老年2型糖尿病患者血糖波动与认知功能障碍的关系2型糖尿病;血糖波动;认知功能障碍']
--------------------------------------------------
['query title label']
['作者单位:南州中学 浅谈初中教学管理如何体现人文关怀初中教育', '教学管理', '人文关怀 1']
['作者单位:南州中学 高中美术课堂教学中藏区本土民间艺术的融入路径藏区', '传统民间艺术', '美术课堂 0']
['作者单位:南州中学 列宁关于资产阶级民主革命向 社会主义革命过渡的理论列宁', '直接过渡', '间接过渡', '资产阶级民主革命', '社会主义革命 0']
['DAA髋关节置换 DAA前侧入路和后外侧入路髋关节置换疗效对比髋关节置换术;直接前侧入路;后外侧入路;髋关节功能;疼痛;并发症 1']
['DAA髋关节置换 DAA全髋关节置换术治疗髋关节病变对患者髋关节运动功能的影响直接前侧入路全髋关节置换术', '髋关节病变', '髋关节运动功能 0']
--------------------------------------------------
['中西方语言与文化的差异 中西方文化差异以及语言体现中西方文化', '差异', '语言体现 0.43203747272491455']
['中西方语言与文化的差异 论中西方文化差异在非言语交际中的体现中西方文化', '差异', '非言语交际 0.4644506871700287']
['中西方语言与文化的差异 中西方体态语文化差异跨文化', '体态语', '非语言交际', '差异 0.4917311668395996']
['中西方语言与文化的差异 由此便可以发现两种语言以及两种文化的差异。 0.5039259195327759']
['中西方语言与文化的差异 文化空缺视域下的中西方体态语对比研究体态语;中西方差异;文化空缺;跨文化交际 0.5056567192077637']
['中西方语言与文化的差异 浅析中西方文化差异在语言中的体现及其对翻译的影响中西方文化', '差异', '语言', '翻译', '影响 0.5060906410217285']
--------------------------------------------------
4.环境和安装说明
(1)运行环境
本实验采用了以下的运行环境进行,详细说明如下,用户也可以在自己 GPU 硬件环境进行:
a. 软件环境:
python >= 3.6
paddlenlp >= 2.2.1
paddlepaddle-gpu >=2.2
CUDA Version: 10.2
NVIDIA Driver Version: 440.64.00
Ubuntu 16.04.6 LTS (Docker)
b. 硬件环境:
NVIDIA Tesla V100 16GB x4卡
Intel® Xeon® Gold 6148 CPU @ 2.40GHz
c. 依赖安装:
pip install -r requirements.txt
#环境安装
!pip install -r requirements.txt
!nvcc --version
## cuda-11.2
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2021 NVIDIA Corporation
Built on Sun_Feb_14_21:12:58_PST_2021
Cuda compilation tools, release 11.2, V11.2.152
Build cuda_11.2.r11.2/compiler.29618528_0
5. Neural Search 快速体验实践(重点!)
PaddleNLP已经基于ERNIE 1.0训练了一个基线模型,如果想快速搭建Neural Search的完整系统,有两种方法,第一种是请参考下面的实现,包含了服务化的完整流程,另一种是使用Pipelines加载,Pipelines已经支持Neural Search训练的模型的载入,可以使用Pipelines的快速的基于Neural Search模型实现检索系统。
5.1. 召回
召回向量抽取服务的搭建请参考:In-batch Negatives, 只需要下载基于ERNIE 1.0的预训练模型,导出成Paddle Serving的格式,然后启动Pipeline Server服务即可
召回向量检索服务的搭建请参考:Milvus, 需要搭建Milvus并且插入检索数据的向量
【注意】如果使用Neural Search训练好的模型,由于该模型是基于ERNIE 1.0训练的,所以需要把 model_name_or_path指定为ernie 1.0,向量抽取结果才能正常。
5.2. 排序
排序服务的搭建请参考 ernie_matching,只需要下载基于ERNIE Gram的预训练模型,导出成Paddle Serving的格式,最后需要启动 Pipeline Serving服务
【注意】如果使用Neural Search训练好的模型,由于该模型是基于ERNIE Gram训练的,所以需要把 model_name_or_path指定为ernie-gram-zh,向量抽取结果才能正常。
5.3. 系统运行(效果展示)含部分bug解决方案
以上召回和排序模型都经过Paddle Serving服务化以后,就可以直接使用下面的命令运行体验:
python3 run_system.py
这里需要对run_system.py代码进行优化一下,不然会出现[0.00703308 0.00505753 0.00439458 0.00474953 0.00432936 0.00410844 ^ SyntaxError: invalid syntax
#修改如下:
#result = np.array(eval(ret.value[0]))
result_str = ret.value[0].strip("[]").split(" ")
result_filtered = [float(num) for num in result_str if num]
result = np.array(result_filtered)
df["distance"] = result[:df.shape[0]]
#df["distance"] = result
输出的结果为:
PipelineClient::predict pack_data time:1656991375.5521955
PipelineClient::predict before time:1656991375.5529568
Extract feature time to cost :0.0161135196685791 seconds
Search milvus time cost is 0.8139839172363281 seconds
PipelineClient::predict pack_data time:1656991376.3981335
PipelineClient::predict before time:1656991376.3983877
time to cost :0.05616641044616699 seconds
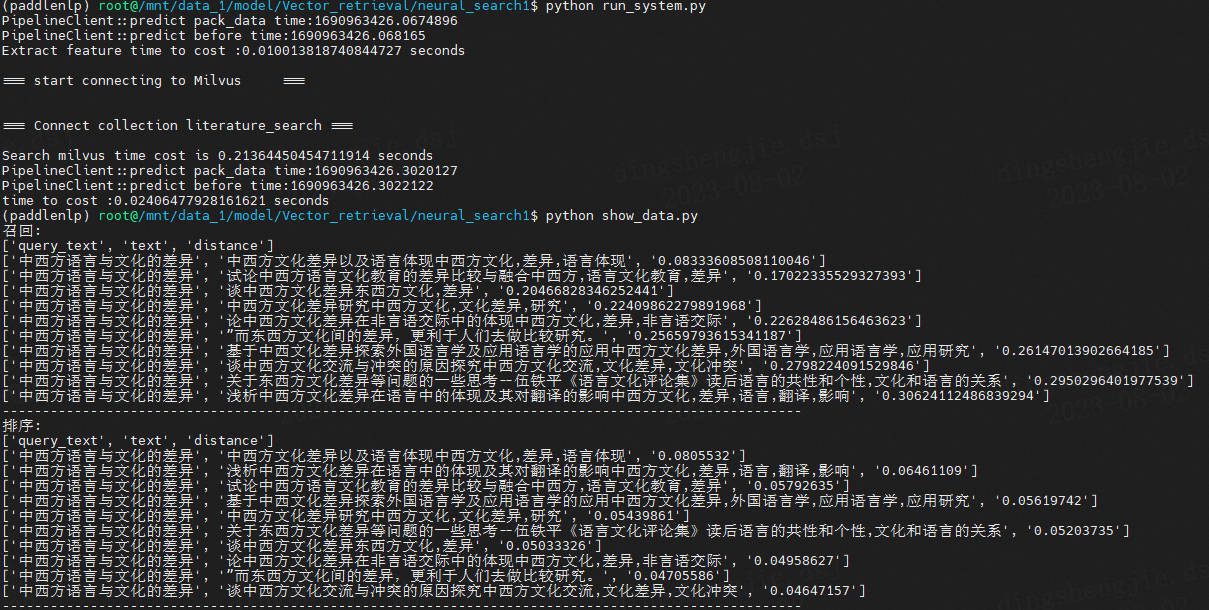
会输出2个文件 recall_result.csv 是召回检索的结果,rank_result.csv 是排序的结果。csv的示例输出下。
官方结果如下:
召回的结果:
中西方语言与文化的差异,港台文化对内地中小学生的负面影响,0.055068351328372955
中西方语言与文化的差异,外来文化在越南的传播与融合,0.05621318891644478
中西方语言与文化的差异,临终关怀中的“仪式”,0.05705389380455017
中西方语言与文化的差异,历史的真实与艺术加工,0.05745899677276611
......
排序的结果:
中西方语言与文化的差异,论中西方教育差异,0.870943009853363
中西方语言与文化的差异,浅析中西方问候语的差异,0.8468159437179565
中西方语言与文化的差异,文化认同及其根源,0.8288694620132446
中西方语言与文化的差异,从历史文化角度分析中西方学校教育的差异,0.8209370970726013
中西方语言与文化的差异,中西医思维方式的差异,0.8150948882102966
中西方语言与文化的差异,浅析中韩餐桌文化差异,0.7751647233963013
......
本人结果:
召回 recall_result.csv:
['query_text', 'text', 'distance']
['中西方语言与文化的差异', '中西方文化差异以及语言体现中西方文化,差异,语言体现', '0.08333608508110046']
['中西方语言与文化的差异', '试论中西方语言文化教育的差异比较与融合中西方,语言文化教育,差异', '0.17022335529327393']
['中西方语言与文化的差异', '谈中西方文化差异东西方文化,差异', '0.20466828346252441']
['中西方语言与文化的差异', '中西方文化差异研究中西方文化,文化差异,研究', '0.22409862279891968']
['中西方语言与文化的差异', '论中西方文化差异在非言语交际中的体现中西方文化,差异,非言语交际', '0.22628486156463623']
['中西方语言与文化的差异', '”而东西方文化间的差异,更利于人们去做比较研究。', '0.25659793615341187']
['中西方语言与文化的差异', '基于中西文化差异探索外国语言学及应用语言学的应用中西方文化差异,外国语言学,应用语言学,应用研究', '0.26147013902664185']
['中西方语言与文化的差异', '谈中西方文化交流与冲突的原因探究中西方文化交流,文化差异,文化冲突', '0.2798224091529846']
['中西方语言与文化的差异', '关于东西方文化差异等问题的一些思考--伍铁平《语言文化评论集》读后语言的共性和个性,文化和语言的关系', '0.2950296401977539']
['中西方语言与文化的差异', '浅析中西方文化差异在语言中的体现及其对翻译的影响中西方文化,差异,语言,翻译,影响', '0.30624112486839294']
----------------------------------------------------------------------------------------------------
排序rank_result.csv:
['query_text', 'text', 'distance']
['中西方语言与文化的差异', '语言及文化.', '0.00721998']
['中西方语言与文化的差异', '文化与语言的关系在中西文化中的映射交际,符号,语言,文化', '0.00718039']
['中西方语言与文化的差异', '中西方文化差异以及语言体现中西方文化,差异,语言体现', '0.00703308']
['中西方语言与文化的差异', '由此便可以发现两种语言以及两种文化的差异。', '0.00614658']
['中西方语言与文化的差异', '浅谈中西言语交际行为中的文化差异交际用语,文化差异,中国,西方', '0.00583243']
['中西方语言与文化的差异', '中西方文化差异的几个显著现象及其原因分析中西方文化,文化差异,词汇,亲属关系,法律', '0.00575102']
['中西方语言与文化的差异', '浅析中西方文化差异在语言中的体现及其对翻译的影响中西方文化,差异,语言,翻译,影响', '0.00564118']
['中西方语言与文化的差异', '汉语和英语均是历史悠久的语言。', '0.00551225']
['中西方语言与文化的差异', '今日,总体来说,华语仍然被看作是保持与中华文化的联系的方式。', '0.00550965']
['中西方语言与文化的差异', '他们的语言接近于汉语;', '0.00547498']
更多涉及内容见:issue,欢迎大家一起共建解决问题
[Bug]: 手把手搭建一个语义检索系统BUG,run.system.py在rank时出错,个人进行了修复,不过返回结果超级小和官方提供的有点出路
这里进行优化记录:
top k 返回控制 通过修改milvus下config文件
MILVUS_HOST = "0.0.0.0"
MILVUS_PORT = 19530
data_dim = 256
top_k = 10
collection_name = "literature_search"
partition_tag = "partition_2"
embedding_name = "embeddings"
index_config = {
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {"nlist": 1000},
}
search_params = {
"metric_type": "L2",
"params": {"nprobe": top_k},
先启动milvus 再开其他两个服务端,不然会报错
Traceback (most recent call last):
File "run_system.py", line 92, in
df = search_in_milvus(result, list_data[0])
File "run_system.py", line 51, in search_in_milvus
for line in results:
TypeError: 'NoneType' object is not iterable
附上案例效果

6. 从头开始搭建自己的检索系统
这里展示了能够从头至尾跑通的完整代码,您使用自己的业务数据,照着跑,能搭建出一个给定 Query,返回 topK 相关文档的小型检索系统。您可以参照我们给出的效果和性能数据来检查自己的运行过程是否正确。
6.1 召回阶段
召回模型训练
我们进行了多组实践,用来对比说明召回阶段各方案的效果:
| 模型 | Recall@1 | Recall@5 | Recall@10 | Recall@20 | Recall@50 | 策略简要说明 |
|---|---|---|---|---|---|---|
| 有监督训练 Baseline | 30.077 | 43.513 | 48.633 | 53.448 | 59.632 | 标准 pair-wise 训练范式,通过随机采样产生负样本 |
| 有监督训练 In-batch Negatives | 51.301 | 65.309 | 69.878 | 73.996 | 78.881 | In-batch Negatives 有监督训练 |
| 无监督训练 SimCSE | 42.374 | 57.505 | 62.641 | 67.09 | 72.331 | SimCSE 无监督训练 |
| 无监督 + 有监督训练 SimCSE + In-batch Negatives | 55.976 | 71.849 | 76.363 | 80.49 | 84.809 | SimCSE无监督训练,In-batch Negatives 有监督训练 |
| Domain-adaptive Pretraining + SimCSE | 51.031 | 66.648 | 71.338 | 75.676 | 80.144 | ERNIE 预训练,SimCSE 无监督训练 |
| Domain-adaptive Pretraining + SimCSE + In-batch Negatives | 58.248 | 75.099 | 79.813 | 83.801 | 87.733 | ERNIE 预训练,SimCSE 无监督训训练,In-batch Negatives 有监督训练 |
从上述表格可以看出,首先利用 ERNIE 3.0 做 Domain-adaptive Pretraining ,然后把训练好的模型加载到 SimCSE 上进行无监督训练,最后利用 In-batch Negatives 在有监督数据上进行训练能够获得最佳的性能。模型下载,模型的使用方式参考In-batch Negatives 。
这里采用 Domain-adaptive Pretraining + SimCSE + In-batch Negatives 方案:
第一步:无监督训练 Domain-adaptive Pretraining
训练用时 16hour55min,可参考:ERNIE 1.0
第二步:无监督训练 SimCSE
训练用时 16hour53min,可参考:SimCSE
第三步:有监督训练
几分钟内训练完成,可参考 In-batch Negatives
召回系统搭建
召回系统使用索引引擎 Milvus,可参考 milvus_system。
中西方语言与文化的差异
下面是召回的部分结果,第一个是召回的title,第二个数字是计算的相似度距离
跨文化中的文化习俗对翻译的影响翻译,跨文化,文化习俗 0.615584135055542
试论翻译过程中的文化差异与语言空缺翻译过程,文化差异,语言空缺,文化对比 0.6155391931533813
中英文化差异及习语翻译习语,文化差异,翻译 0.6153547763824463
英语中的中国文化元素英语,中国文化,语言交流 0.6151996850967407
跨文化交际中的文化误读研究文化误读,影响,中华文化,西方文明 0.6137217283248901
在语言学习中了解中法文化差异文化差异,对话交际,语言 0.6134252548217773
从翻译视角看文化差异影响下的中式英语的应对策略文化差异;中式英语现;汉英翻译;动态对等理论 0.6127341389656067
归化与异化在跨文化传播中的动态平衡归化,异化,翻译策略,跨文化传播,文化外译 0.6127211451530457
浅谈中西言语交际行为中的文化差异交际用语,文化差异,中国,西方 0.6125463843345642
翻译中的文化因素--异化与归化文化翻译,文化因素,异化与归化 0.6111845970153809
历史与文化差异对翻译影响的分析研究历史与文化差异,法汉翻译,翻译方法 0.6107486486434937
从中、韩、美看跨文化交际中的东西方文化差异跨文化交际,东西方,文化差异 0.6091923713684082
试论文化差异对翻译工作的影响文化差异,翻译工作,影响 0.6084284782409668
从归化与异化看翻译中的文化冲突现象翻译,文化冲突,归化与异化,跨文化交际 0.6063553690910339
中西方问候语的文化差异问候语,文化差异,文化背景 0.6054259538650513
中英思维方式的差异对翻译的影响中英文化的差异,中英思维方式的差异,翻译 0.6026732921600342
略论中西方语言文字的特性与差异语言,会意,确意,特性,差异 0.6009351015090942
......
6.2 排序阶段
排序阶段有2种方案,第一种是ernie_matching使用的模型是
ERNIE-3.0-Medium-zh,用时 20h;第二种是基于RocketQA的排序模型cross_encoder,训练用时也是20h左右。
排序阶段的效果评估:
| 模型 | AUC |
|---|---|
| Baseline: In-batch Negatives | 0.582 |
| pairwise ERNIE-Gram | 0.791 |
| CrossEncoder:rocketqa-base-cross-encoder | 0.804 |
同样输入文本:
中西方语言与文化的差异
排序阶段的结果展示如下,第一个是 Title ,第二个数字是计算的概率,显然经排序阶段筛选的文档与 Query 更相关:
中西方文化差异以及语言体现中西方文化,差异,语言体现 0.999848484992981
论中西方语言与文化差异的历史渊源中西方语言,中西方文化,差异,历史渊源 0.9998375177383423
从日常生活比较中西方语言与文化的差异中西方,语言,文化,比较 0.9985846281051636
试论中西方语言文化教育的差异比较与融合中西方,语言文化教育,差异 0.9972485899925232
中西方文化差异对英语学习的影响中西方文化,差异,英语,学习 0.9831035137176514
跨文化视域下的中西文化差异研究跨文化,中西,文化差异 0.9781349897384644
中西方文化差异对跨文化交际的影响分析文化差异,跨文化交际,影响 0.9735479354858398
探析跨文化交际中的中西方语言差异跨文化交际,中西方,语言差异 0.9668175578117371
中西方文化差异解读中英文差异表达中西文化,差异表达,跨文化交际 0.9629314541816711
中西方文化差异对英语翻译的影响中西方文化差异,英语翻译,翻译策略,影响 0.9538986086845398
论跨文化交际中的中西方文化冲突跨文化交际,冲突,文化差异,交际策略,全球化 0.9493677616119385
中西方文化差异对英汉翻译的影响中西方文化,文化差异,英汉翻译,影响 0.9430705904960632
中西方文化差异与翻译中西方,文化差异,翻译影响,策略方法,译者素质 0.9401137828826904
外语教学中的中西文化差异外语教学,文化,差异 0.9397934675216675
浅析西语国家和中国的文化差异-以西班牙为例跨文化交际,西语国家,文化差异 0.9373322129249573
中英文化差异在语言应用中的体现中英文化,汉语言,语言应用,语言差异 0.9359155297279358
....
7.总结
语义索引(可通俗理解为向量索引)技术是搜索引擎、推荐系统、广告系统在召回阶段的核心技术之一。语义索引模型的目标是:给定输入文本,模型可以从海量候选召回库中快速、准确地召回一批语义相关文本。语义索引模型的效果直接决定了语义相关的物料能否被成功召回进入系统参与上层排序,从基础层面影响整个系统的效果。
本项目从无监督训练 Domain-adaptive Pretraining+无监督训练 SimCSE+有监督训练In-batch Negatives结合,使用 Milvus 搭建召回系统,然后使用训练好的语义索引模型,抽取向量,插入到 Milvus 中,然后进行检索。排序阶段采用ernie_matching和基于RocketQA的排序模型cross_encoder实现全流程自己的检索系统,欢迎大家尝试
性能对比
| 硬件配置 | 向量库数据量 | 提取特征所需时间 | milvus检索所需时间 | 排序所需时间 | 总耗时 |
|---|---|---|---|---|---|
| CPU 12核 2.5GHz | 1000w 大小45GB左右 | 64.5ms | 258.3ms | 871.6 ms | 1.19s |
| CPU + Tesla V100 32G | 1000w 大小45GB左右 | 10ms | 213.6ms | 24.1ms | 0.25s |
语义搜索系列文章全流程教学:
语义检索系统:基于无监督预训练语义索引召回:SimCSE、Diffcse:
语义检索系统:基于in-batch Negatives策略的有监督训练语义召回:
语义检索系统:基于Milvus 搭建召回系统抽取向量进行检索,加速索引:
语义检索系统:基于ERNIE-Gram /RocketQA实现数据精排序:
基于Milvus+ERNIE+SimCSE+IBN实现学术文献语义检索系统完整版:
更多文本匹配方案参考:
特定领域知识图谱融合方案:技术知识前置【一】-文本匹配算法:
特定领域知识图谱融合方案:文本匹配算法Simnet、Diffcse【二】:
特定领域知识图谱融合方案:文本匹配算法ERNIE-Gram单塔等诸多模型【三】:
基于文心大模型套件ERNIEKit实现文本匹配算法:
特定领域知识图谱融合方案:学以致用-问题匹配鲁棒性评测比赛验证【四】:
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。
参考文献
[1] Tianyu Gao, Xingcheng Yao, Danqi Chen: SimCSE: Simple Contrastive Learning of Sentence Embeddings. EMNLP (1) 2021: 6894-6910
[2] Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, Wen-tau Yih, Dense Passage Retrieval for Open-Domain Question Answering. Preprint 2020.
[3] Dongling Xiao, Yu-Kun Li, Han Zhang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang:
ERNIE-Gram: Pre-Training with Explicitly N-Gram Masked Language Modeling for Natural Language Understanding. NAACL-HLT 2021: 1702-1715
[4] Yu Sun, Shuohuan Wang, Yu-Kun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu:
ERNIE: Enhanced Representation through Knowledge Integration. CoRR abs/1904.09223 (2019)
文章来源:华为云社区
